你的不可變引用
不是你的不可變引用
@wusyong, 吳昱緯
tl;dr
&Tmeans "shared reference"&mut Tmeans "exclusive reference"
{{% section %}}
Reference & Borrowing
struct Point {
x: u32,
y: u32,
}
fn print_point(pt: &Point) {
println!("x={} y={}", pt.x, pt.y);
}
Reference & Borrowing
fn embiggen_x(pt: &Point) {
pt.x = pt.x * 2;
}
error[E0594]: cannot assign to `pt.x` which is behind a `&` reference
--> src/main.rs
|
1 | fn embiggen_x(pt: &Point) {
| ------ help: consider changing this to be a mutable reference: `&mut Point`
2 | pt.x = pt.x * 2;
| ^^^^^^^^^^^^^^^ `pt` is a `&` reference, so the data it refers to cannot be written
Reference & Borrowing
fn embiggen_x(pt: &mut Point) {
pt.x = pt.x * 2;
}
Holup
impl AtomicU32 {
pub fn store(&self, val: u32, order: Ordering);
}
static COUNTER: AtomicU32 = AtomicU32::new(0);
fn reset() {
COUNTER.store(10, Ordering::SeqCst);
}
{{% /section %}}
{{% section %}}
Multiprocessor Programming
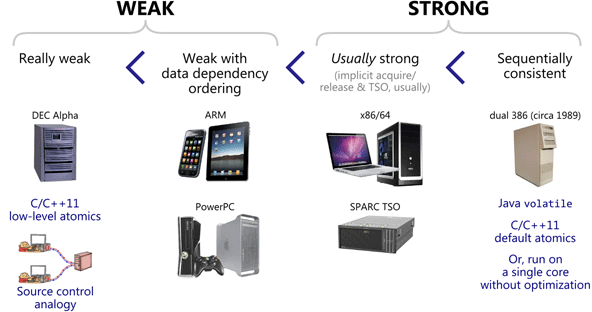
Memory Ordering

Cache
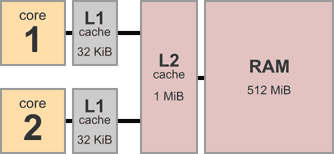
MESI protocol
Modified (M) - modified (dirty). Need to write back data to main memory.
Exclusive (E) - only exists in this cache. Doesn't need to be synced (clean).
Shared (S) - might exist in other caches. Is current with main memory (clean).
Invalid (I) - cache line is invalid. Another cache has modified it.
{{% /section %}}
{{% section %}}
Atomic type
std::sync::atomic::Ordering
Relaxed < Aquire/Release | AcqRel < SeqCst
Relaxed
In current CPU:
- Prevent compiler from reordering these instructions
- Might reorder all other memory accesses (on weakly ordered CPUs)
- Okay to use this in counter but not flag.
Relaxed
In observer CPU:
- Free to reorder any other memory access
- Still can't reorder Relaxed instructions
Relaxed
on strong ordered CPUs:
- They use Acquire/Release by default
- So this will only serve as hint for compiler
Aquire
In current CPU:
- Paired with a Release to form a memory sandwich
- Any memory operation written after the Acquire access stays after it
- Weakly ordered CPUs might need instructions like memory fence (MFENCE)
Aquire
In observer CPU:
- Doesn't modify memory, there is nothing to observe.
- Still able to see all memory operations happening from the Acquire load, and to the Release store (global synchronization)
Aquire
on strong ordered CPUs:
- Used by default, so this is basically no-op
Release
In current CPU:
- Paired with a Aquire to form a memory sandwich
- Any memory operation written before the Release memory ordering flag stays before it
- Weakly ordered CPUs might need instructions like memory fence (MFENCE)
- Make sure other cores see all these operations.
Release
In order to make sure global synchronization, we could do either:
- An Acquire load must ensure that it processes all messages and if any other core has invalidated any memory we load, it must fetch the correct value.
- A Release store must be atomic and invalidate all other caches holding that value before it modifies it.
Release
In observer CPU:
- Might not see these changes in any specific order
- Unless itself uses an Acquire load of the memory
- If so, it will see all memory which has been modified between the Acquire and the Release, including the Release store itself.
Release is often used together with Acquire to write locks.
Release
on strong ordered CPUs:
- Shared value are invalidated in all L1 caches where the value is present before it is modified
- Acquire load will already have an updated view of all relevant memory, and a Release store will instantly invalidate any cache lines which contain the data on other cores.
- So that's why it's no-op
AcqRel
- Just Acquire/Release literally
SeqCst (Sequential Consistency)
8.2.3.4 Loads May Be Reordered with Earlier Stores to Different Locations The Intel-64 memory-ordering model allows a load to be reordered with an earlier store to a different location. However, loads are not reordered with stores to the same location.
SeqCst
let x = X.load(Ordering::Acquire);
X.store(val | x, Ordering::Release); // 之前不同位置的寫入
let y = Y.load(Ordering::Acquire); // 讀取
// 可能會被 CPU 變更成
let x = X.load(Ordering::Acquire);
let y = Y.load(Ordering::Acquire);
X.store(val | x, Ordering::Release);
SeqCst
8.2.3.9 Loads and Stores Are Not Reordered with Locked Instructions The memory-ordering model prevents loads and stores from being reordered with locked instructions that execute earlier or later. The examples in this section illustrate only cases in which a locked instruction is executed before a load or a store. The reader should note that reordering is prevented also if the locked instruction is executed after a load or a store.
SeqCst
In observer CPU:
- Sequential Consistency: no other memory operations, reads or writes, will happen in between.
- Single total modification order:
SeqCst is the strongest of the memory orderings. It also has a slightly higher cost than the others.
{{% /section %}}
{{% section %}}
Reference in Rust
&Tmeans "shared reference"&mut Tmeans "exclusive reference"
Interior Mutability
The term for safe APIs that support mutation through a shared reference in Rust is "interior mutability".
UnsafeCell<T>
- the only way to hold data that is mutable through a shared reference
- it provides method to return raw pointer
Cell<T>
- !Sync / !Send
- no way to get the content from reference, all access done by copying data
RefCell<T>
- !Sync / !Send
- dynamically checked borrow rules
Mutex<T>
- only one of the references may operate on the inner T at a time
RwLock<T>
- either all reference used for reading
- or only one for writing
{{% /section %}}
{{% section %}}
Thanks!
{{% /section %}}